SCOPE: Scene-Contextualised Incremental Few-Shot 3D Segmentation
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Findings 2026
†Corresponding authors.
vgthengane (at) gmail (dot) com
Abstract
Incremental Few-Shot (IFS) segmentation aims to learn new categories over time from only a few annotations. Although widely studied in 2D, it remains underexplored for 3D point clouds. Existing methods suffer from catastrophic forgetting or fail to learn discriminative prototypes under sparse supervision, and often overlook a key cue: novel categories frequently appear as unlabelled background in base-training scenes. We introduce SCOPE (Scene-COntextualised Prototype Enrichment), a plug-and-play background-guided prototype enrichment framework that integrates with any prototype-based 3D segmentation method. After base training, a class-agnostic segmentation model extracts high-confidence pseudo-instances from background regions to build a prototype pool. When novel classes arrive with few labelled samples, relevant background prototypes are retrieved and fused with few-shot prototypes to form enriched representations without retraining the backbone or adding parameters. Experiments on ScanNet and S3DIS show that SCOPE achieves SOTA performance, improving novel-class IoU by up to 6.98% and 3.61%, and mean IoU by 2.25% and 1.70%, respectively, while maintaining low forgetting.
Method
SCOPE is a plug-and-play background-guided prototype enrichment framework for incremental few-shot 3D segmentation.
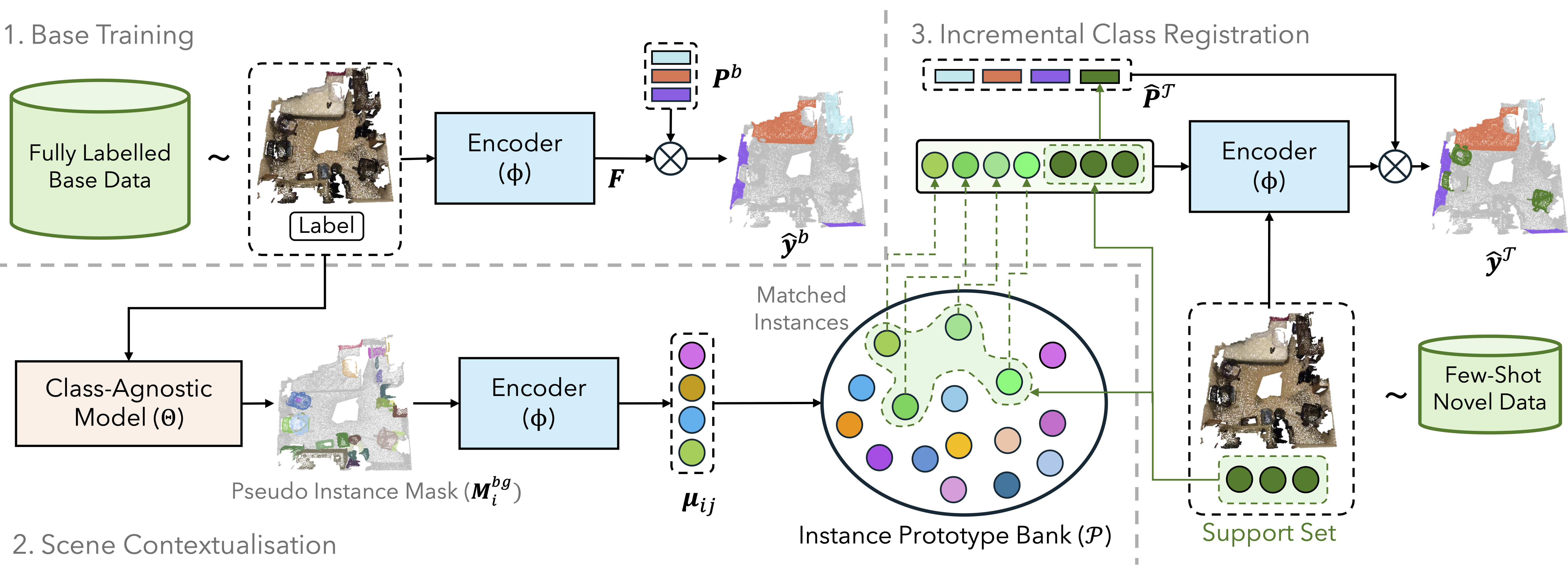
Pipeline overview:
- Train a base model with prototype-based 3D segmentation.
- Use a class-agnostic segmenter to mine high-confidence pseudo-instances from background regions.
- Build a reusable background prototype pool from these pseudo-instances.
- At each incremental step, retrieve and fuse relevant background prototypes with few-shot prototypes.
- Adapt to new classes without retraining the backbone and without introducing extra learnable parameters.
Results
SCOPE improves both novel-class recognition and overall segmentation quality across incremental few-shot settings.
Key outcomes:
- On ScanNet and S3DIS, SCOPE achieves state-of-the-art performance for incremental few-shot 3D segmentation.
- Novel-class IoU gains reach up to 6.98% and 3.61%.
- Mean IoU gains reach up to 2.25% and 1.70%.
- Strong transfer to new classes while keeping forgetting low.
BibTeX
@inproceedings{thengane2026scope,
title={SCOPE: Scene-Contextualized Incremental Few-Shot 3D Segmentation},
author={Thengane, Vishal and An, Zhaochong and Huang, Tianjin and Phung, Son Lam and Bouzerdoum, Abdesselam and Yin, Lu and Zhao, Na and Zhu, Xiatian},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Findings},
year={2026}
}